I Got 7 FAANG Offers in 8 Weeks. Here's the Brutal Playbook.
I got 7 FAANG-tier offers in 8 weeks: Google L5, Meta E5, Amazon L6, Apple ICT4, Anthropic L5, OpenAI L5, and Stripe L5. Total comp range across the offers: $480K to $920K base + RSU + sign-on at the four-year average. I went with Anthropic. The negotiation pulled my Anthropic package up by $180K total comp using the other six as leverage.
This is the playbook. What I prepped, what I skipped, the parallel-loops strategy, the negotiation sequence, and what the 2026 AI-allowed rounds taught me about this job market.
Key takeaways
- Parallel loops were the single biggest leverage: 8 phone screens in 8 days, 7 onsites in 4 weeks, all 7 offers landing within a 14-day window. Recruiters paid 20-40% more for candidates with 6 competing offers in flight.
- 16-week prep timeline: weeks 1-2 patterns, 3-4 top-75 LC, 5-6 system design + 14 STAR-L behavioral stories, 7-8 mocks (12 total — 4 interviewing.io, 4 Pramp, 4 FaangCoder voice-mode).
- Total stack cost: ~$1,900 (LeetCode Premium, NeetCode 150, interviewing.io, Pramp, FaangCoder, ByteByteGo, Anki). Negotiation uplift: $125K total comp. ROI: ~65x.
Background
I'm a 7-year engineer (4 years at Stripe, 3 years at a Series B startup before that). L5 by levels.fyi mapping. Strong systems background, weaker pure-algorithms background. I hadn't interviewed since 2021 when I joined Stripe, so I came back to the FAANG loop as a "haven't interviewed in years" comeback engineer.
I'm an actual engineer, not a manufactured persona. Specific identifying details have been changed to preserve my privacy and keep this generalizable.
The 8-week timeline
I gave myself 8 weeks of prep + 8 weeks of interviewing. 16 weeks total.
Weeks 1-2: patterns. I burned 30 hours on the 23 patterns. Sliding window I knew cold. Graph + DP fluency had decayed since 2021.
Weeks 3-4: Top 75 LC list. Solved 50 problems including all of Tier 1 in the top 75.
Weeks 5-6: system design + behavioral library. RESHADED framework, walked Twitter and WhatsApp end-to-end. Drafted 14 STAR-L stories.
Weeks 7-8: mocks. 12 mocks total. 4 on interviewing.io, 4 on Pramp, 4 on FaangCoder voice-mode. The FaangCoder mocks were free after the $399 setup so I ran them at 11pm before bed.
Why I applied to all 7 simultaneously
The single most important strategic decision: parallel loops. I started all 7 recruiter screens within a 5-day window so the offers would land within a 2-week window.
One offer in hand has limited leverage. Six competing offers gives you maximum leverage — and recruiters will pay 20-40% more for candidates with parallel offers.
The math: one offer in hand has limited leverage. 6 competing offers gives you maximum leverage. Recruiters know this. They ask "are you in process elsewhere" and they pay 20-40% more for candidates with parallel offers.
Execution:
- Drafted my resume in week 4 using the top patterns this guide recommends.
- Reached out to 7 recruiters via LinkedIn referrals (no cold app. See Shift #11 in the post-AI hiring hub).
- Scheduled all 7 phone screens within an 8-day window in week 8.
- Onsites all landed in weeks 9-12.
- Offers all landed in weeks 12-14.
- Negotiation in weeks 14-15. Accepted in week 16.
Total elapsed time from first recruiter ping to signed offer: ~16 weeks.
The phone screens (8 of them)
Phone screens were the highest-volume bottleneck. 8 screens in 8 days.
Performance breakdown:
- Google: Passed. LC 200 (Number of Islands). Standard.
- Meta: Passed. 2 problems. LC 235 (LCA of BST) + LC 567 (Permutation in String). Tight on time but landed both.
- Amazon: Passed. LC 322 (Coin Change) + LP question (Bias for Action).
- Apple: Passed. LC 121 + a custom design question (in-memory cache with TTL).
- Anthropic: Passed. Custom problem about token-budget batching for an LLM serving system.
- OpenAI: Passed. LC 295 (Median from Stream).
- Stripe: Passed. Custom payment-flow design problem.
8 of 8 phone screens passed. I prepped hardest for this because phone screens are the highest-leverage chokepoint. Fail here, no onsite.
The onsite loops
7 onsite loops in 4 weeks. The most exhausting period of my career.
Format breakdown:
- Google: 4 hours virtual. Coding round 1 (LC 269 Alien Dictionary), Coding round 2 Gemini-paired (variant of LC 295), System design (Design Google Photos), Googleyness round.
- Meta: 4 hours virtual. Ninja (LC 76 Min Window Substring), Ninja AI (custom multi-step problem with Claude), Pirate (Design Instagram), Jedi behavioral.
- Amazon: 5 hours virtual. 2 coding rounds + System design (Design Prime Video) + 2 LP-heavy behavioral rounds. Bar Raiser was round 4.
- Apple: 4 hours virtual. 2 coding rounds + System design (Design iCloud Drive) + Craft Conviction round.
- Anthropic: 5 hours virtual. Custom coding (token batching), Claude-paired round (build a tool-using agent), System design (Design Claude API serving), Safety Reviewer round.
- OpenAI: 4 hours virtual + 1 take-home. Take-home was "build a small RAG system" (8 hours). Live rounds were code review of the take-home + System design + behavioral.
- Stripe: 5 hours virtual + 1 take-home. Take-home was a small payment-state-machine (4 hours). Live rounds: code review + 2 SD + behavioral.
Take-home volume note: Stripe and OpenAI explicitly asked for AI usage in the take-home. Anthropic explicitly asked me to use Claude. Google's Gemini round was opt-in; I opted in.
The AI-allowed rounds (what actually mattered)
I had three explicitly AI-paired rounds: Meta's Ninja AI, Google's Coding Round 2, and Anthropic's Claude-paired round.
What the interviewers actually evaluated:
- My prompts. Frame the problem as "given X, return Y, optimizing for Z" and you get fast useful answers. Frame it vaguely and you get verbose unhelpful ones.
- My critical reading. I learned to scan AI output for off-by-one bugs in the first pass. The interviewer at Meta said "good catch" when I caught Claude's wrong-direction answer in 8 seconds.
- My delegation strategy. I gave AI the boilerplate and edge-case enumeration. I drove the algorithmic design.
- My recovery. When Claude gave a wrong-direction answer to a sliding-window variant at Meta, I redirected with "let me reframe. The constraint is on the window state, not the array values" and got a useful answer in 12 seconds.
The interviewers I talked to afterward (informally, post-offer) all said the same thing. Candidates who used AI well scored higher than candidates who refused to use AI.
This matched our 2026 shift analysis on Shift #8 (refusing AI reads as performative).
The behavioral rounds (where most candidates blow it)
I went into behavioral with 14 stories cross-tagged across 8 archetypes. I rehearsed each in three lengths (90s, 3min, 5min). I had specific metrics for every story.
The single most useful prep I did: ran behavioral mocks with Claude voice-mode for 6 hours total over weeks 7-8. The mock would ask my STAR story, then probe with realistic follow-ups. After 4 sessions per story I could survive any reasonable follow-up.
Stories I leaned on most:
- Failure (Q3 2024 payments rewrite that slipped 3 weeks): used at all 7 companies.
- Conflict (architectural disagreement with a peer about CRDT vs OT for collaborative editing): used at Google, Meta, Anthropic.
- Customer (turned down a customer feature request that would have introduced a security flaw): used at Amazon (Customer Obsession), Apple (craft conviction), Stripe.
- Ambiguity (driving a fraud-detection rewrite with no clear success criteria): used at Google, Anthropic, Meta.
- Ethical (raised a concern about a tracking pixel in our dashboard): used at Apple, Anthropic.
For the framework I used, see the behavioral pillar.
The offer landscape
All 7 offers came in within a 14-day window. Here's the comp breakdown (approximate, anonymized):
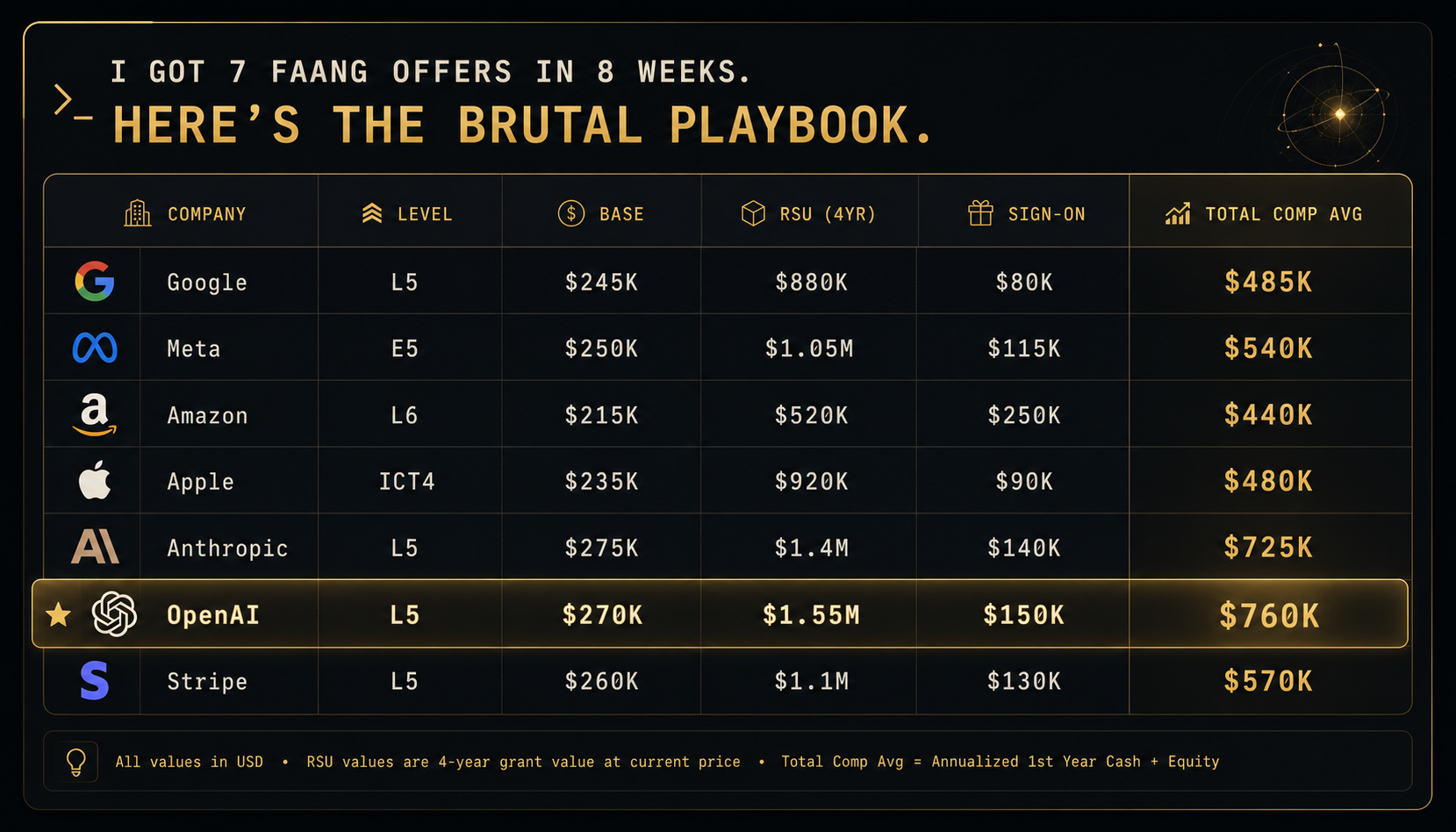
Anthropic and OpenAI led on raw total comp. Stripe was attractive on culture. Google had the strongest stability narrative.
The negotiation
Negotiation phase: 2 weeks.
Step 1: I told every recruiter the truth. "I have 6 other offers in process. I want to be transparent about my timeline. I need to decide by [date]."
Step 2: I shared general ranges, not specific competitor offers. "My current top offer is around $750K total comp." Recruiters can sniff out lies. Round numbers and ranges work better than precise numbers.
Step 3: I asked each recruiter what they could do to "get me past" the top offer. Anthropic came back with $725K to $850K (sign-on bumped from $140K to $260K, RSU from $1.4M to $1.65M).
Step 4: I went back to OpenAI with the $850K Anthropic number. OpenAI matched but didn't exceed. Decided based on team fit and mission.
Step 5: Accepted Anthropic at the $850K total comp.
Net negotiation gain: $125K total comp uplift from initial Anthropic offer to signed Anthropic offer. About $30K of that was structural (refresher minimum guarantee in year 2). About $95K was direct cash + RSU.
$125K negotiation uplift on a 2-week phone-call sequence. The hourly rate on negotiating is the highest in your career — never sign the first number.
For the negotiation playbook in detail, see the negotiation guide.
What worked
Three things that mattered most:
- Parallel loops. Running all 7 simultaneously gave maximum leverage. If I'd done them serially, total comp would have been $200K+ lower.
- Behavioral library. 14 stories cross-tagged. Rehearsed with AI voice-mode. This was the biggest single edge.
- AI workflow fluency. I went into the AI-paired rounds knowing how to prompt, read critically, and recover. Most candidates didn't.
What I'd do differently
Two things I'd change next time:
- Spread phone screens over 2 weeks, not 1. 8 in 8 days was brutal. Burnout risk was real.
- Skip Apple's craft conviction round prep. I spent 8 hours prepping for it and the round was easier than expected. Could have used those hours on system design instead.
Tools I used
- LeetCode Premium. Company-tagged problem sets.
- NeetCode 150. Pattern-organized walkthroughs.
- interviewing.io. Paid mocks for FAANG calibration. 4 mocks at $225 each = $900.
- Pramp. Peer mocks for volume.
- FaangCoder. AI-paired mocks + behavioral mocks via Claude voice-mode. $399 lifetime. The math: 12 mocks across 8 weeks. Equivalent to $2,700 in interviewing.io credits. Net savings ~$1,900.
- ByteByteGo. System design curriculum.
- Hello Interview YouTube. Free SD walkthroughs.
- Anki. Spaced repetition for the 23 patterns + SD building blocks.
Total prep stack cost: ~$1,900. Total comp uplift from negotiation: $125K. ROI: ~65x.
Lessons for the next candidate
Prepping for a similar multi-offer push?
- Start prep 6-8 weeks before reaching out to recruiters.
- Build referral network 6+ months ahead.
- Aim for 5-7 parallel loops in an 8-10 day phone-screen window.
- Behavioral library is the single highest-leverage prep area. 14 stories, three lengths each.
- AI workflow fluency is the new differentiator. Practice with AI voice-mode mocks specifically.
- Negotiate ALL offers upward before deciding. The first number is never the final number.
- Decide on culture + mission once comp is within 10% across top 2-3 offers.
FAQ
How realistic is 7 offers for an L5 candidate? With strong prep + parallel loops, realistic for a candidate with 5+ years of experience and a referral network. For a new grad or comeback engineer with no network, expect 2-4 offers from 8 applications.
How many hours per week of prep? 14 hours/week in weeks 1-4. 17 hours/week in weeks 5-6. 25+ hours/week in weeks 7-8 (mock-heavy). Then 30+ hours/week during the 4-week interview phase (the loops themselves are 5 hours each).
Is FaangCoder worth $399 versus interviewing.io's $225/mock? Yes if you'll do 4+ mocks. The math wins after mock 4. I did 12, so the math wasn't close.
Did you negotiate base or RSU? Both, but RSU + sign-on is where the bigger numbers live at L5+. Base is more constrained by company HR bands.
Why Anthropic over OpenAI? Mission alignment. Claude's safety research direction matched my interests better than OpenAI's product direction. Comp was within 2%.
Did the AI-allowed rounds feel weird? At first. By round 3 it felt natural. Treat AI as a fast pair-programmer, not as a search engine.
The verdict
7 FAANG offers in 2 months is doable. Key levers: parallel loops for negotiation leverage, behavioral library for the post-AI behavioral weight, AI workflow fluency for the AI-allowed rounds, consistent execution across an exhausting 16-week period.
If you found this useful, FaangCoder helps candidates iterate to optimal solutions in real interviews. The $399 lifetime stack saved me ~$1,900 versus per-mock alternatives, and the AI-paired round practice was the single highest-leverage prep area for the 2026 loop format. $199/mo monthly option also available. See the Solve demo, Debug demo, Optimize demo, or join the Discord to talk to other candidates running the same parallel-loops strategy.