System Design Bar Doubled in 2026. RESHADED Beats It.
System design is the FAANG round that separates engineers from senior engineers. In 2022 it was an L5+ filter. In 2026 it shows up at L3-L4 phone screens (in scaled-down form), and at L5+ it's two rounds, not one. The 2026 system design bar is meaningfully harder than the 2020 bar. AI tools handle implementation details now, freeing the interviewer to probe judgment, trade-offs, and operational maturity.
SD moved earlier because it's the one signal AI can't pre-solve in real time. Verbal trade-offs and dynamic interviewer probes still beat any LLM in 2026.
You get the framework (RESHADED), eight worked designs covering the most-asked FAANG SD problems, the leveling rubric (what L4 versus L5 versus L6 versus L7 looks like), and the 2026-specific updates that pre-2024 SD content on YouTube misses.
Why system design moved earlier
In 2022, system design was reserved for L5+. New grads didn't see SD until they had 2-3 years of work experience.
In 2026, every L3-L4 onsite at Google, Meta, and Stripe includes scaled-down SD ("design a URL shortener for 10K users"). Reasoning:
- SD is harder for candidates to fake with AI on a whiteboard. Verbal back-and-forth, dynamic interviewer probes, hand-drawn diagrams. All AI-resistant.
- SD is a strong proxy for production engineering judgment. Interviewers care more about judgment than algorithm speed in 2026.
- SD scales by level naturally. The same prompt ("design Twitter") can be probed at L3, L5, or L7 depth.
For the broader 2026 shift context, see What Changed in FAANG Interviews After ChatGPT.
TL;DR — the RESHADED framework
For position-zero featured snippet: a 7-step framework for any system design interview.
- R. Requirements. Functional + non-functional. Ask 2-4 clarifying questions.
- E. Estimation. Capacity. QPS, storage, bandwidth. Order-of-magnitude only.
- S. Storage. Schema and database choice. SQL versus NoSQL. Sharding strategy.
- H. High-level design. Boxes and arrows. Major components.
- A. APIs. Endpoint signatures. Request/response shapes.
- D. Deep dive. Pick 1-2 components and go deep on a trade-off the interviewer cares about.
- E. Edge cases + scaling. Failure modes. Hotspots. Bottlenecks.
- D. Done? Wrap up. Recap. Mention what you'd do next.
Yes, it's RESHADED with two D's. The mnemonic is intentional. Memorize it.
Step 1: Requirements (5-7 minutes)
The biggest mistake candidates make is jumping straight to design. Spend 5-7 minutes on requirements.
Functional requirements: what the system does. For "design Twitter": post tweets, follow users, see a feed, like tweets.
Non-functional requirements: how the system behaves. Latency targets, availability, consistency model, scale.
Ask these clarifying questions in priority order:
- What's the read/write ratio? (Twitter: ~100:1 reads to writes. This drives caching strategy.)
- What's the scale? (Twitter: ~250M DAU, ~500M tweets/day.)
- What latency? (Twitter feed: 200ms p99 read.)
- Consistency or availability priority? (Twitter: availability. Eventual consistency on feed is fine.)
Take notes on the whiteboard. The interviewer will reference them later.
Step 2: Estimation (3-5 minutes)
Order-of-magnitude estimation. The interviewer doesn't care about precision; they care that you can do back-of-envelope math.
For Twitter:
- 250M DAU.
- 5 tweets/day average post rate (across all users, including read-only) → ~1.2B tweets/day → ~14K writes/sec average, ~50K writes/sec peak.
- 100x reads → ~1.4M reads/sec average, ~5M reads/sec peak.
- 280 chars/tweet + metadata ~1KB → ~1TB/day storage growth → ~365TB/year.
- Bandwidth: 5M reads * 1KB = 5GB/sec read bandwidth peak.
Round generously. Don't pretend to be precise.
Step 3: Storage (5-7 minutes)
Pick database type per data category. For Twitter:
- Tweets. Wide-column store (Cassandra, DynamoDB) sharded by user_id. Cassandra wins on write throughput.
- User graph (follows). Dedicated graph store, OR materialized in a wide-column store with denormalization.
- Timeline cache. Redis with sorted sets, sharded by user_id.
- Media. Object store (S3) with CDN edge.
- Metrics. Time-series store (InfluxDB or Prometheus, depending on retention).
Sharding strategy: consistent hashing on user_id for tweets and timelines. Hot-shard mitigation: detect hot users (celebrities), separate to their own shards or fan-out-on-read.
Step 4: High-level design (5-7 minutes)
Boxes and arrows. Major components for Twitter:
- Mobile/Web client → CDN → Load Balancer → API Gateway → application services (Tweet Service, User Service, Timeline Service, Media Service, Notification Service) → respective data stores.
- Async path: Tweet Service writes → Kafka → Fanout Service → Timeline Cache (Redis).
- Read path: Timeline Service reads from Timeline Cache → falls back to Tweet Service → returns to client.
Draw it on the whiteboard or in the shared editor. Make sure each box has an arrow with a verb on it ("write", "fetch", "publish").
Step 5: APIs (3-5 minutes)
Endpoint signatures. For Twitter:
POST /tweetsbody{user_id, content, media?}→{tweet_id, timestamp}GET /timeline/{user_id}?cursor=X&limit=50→{tweets: [...], next_cursor}POST /followbody{follower_id, followee_id}→{ok}
Note the cursor-based pagination (not offset). Note the limit parameter. Note the optional media field. These small details signal seniority.
Step 6: Deep dive (10-15 minutes)
The most important step. The interviewer will probe one or two components. You drive the deep dive.
For Twitter, the canonical deep dive is the fanout strategy:
- Fanout-on-write (push). When a user posts, write the tweet ID to every follower's timeline cache. Pros: read is O(1) cache lookup. Cons: write amplification. A celebrity with 100M followers triggers 100M writes per tweet.
- Fanout-on-read (pull). When a user reads timeline, fetch latest tweets from every followed user, merge. Pros: write is O(1). Cons: read gets expensive if a user follows many people.
- Hybrid. Push for normal users (< 1M followers), pull for celebrities. Most production systems use hybrid (Twitter, Instagram).
Discuss the trade-off explicitly. Mention the celebrity-shard mitigation. Explain how you'd implement the hybrid threshold (configurable, based on follower count).
The deep dive is where interviewers read seniority signal. L3-L4 candidates often skip the deep dive or stay shallow. L5+ candidates volunteer it.
Skip the deep dive at L5 and you've underperformed regardless of how clean the high-level diagram looked. Volunteer it before the interviewer asks.
Step 7: Edge cases + scaling (3-5 minutes)
Failure modes. Hotspots. Bottlenecks.
For Twitter:
- Failure modes. Redis cache fails → fall back to wide-column read (slower but available). Kafka backs up → fanout latency spikes. Alert on Kafka lag.
- Hotspots. Celebrity users. World-event tweets that go viral within minutes. Mitigation: separate celebrity shards, edge caching for trending content.
- Bottlenecks. Fanout is the canonical bottleneck. The hybrid push/pull split addresses it.
Step 8: Wrap up (1-2 minutes)
Recap what you designed. Mention 2-3 things you'd build next if you had more time. Examples: search service (full-text on tweets), trending topic service (real-time aggregation), DM service (point-to-point messaging).
The wrap-up is what the interviewer remembers. Make it crisp.
The 8 most-asked FAANG SD problems
By frequency from our 2024-2026 dataset:
- Design Twitter / Instagram / News Feed. The canonical fanout problem. Asked at Meta, Google, Amazon.
- Design URL Shortener (bit.ly). The canonical hash + KV problem. Asked at every FAANG, every level.
- Design WhatsApp / chat. The canonical real-time messaging problem. Asked at Meta L5+, Google L5+.
- Design YouTube / video streaming. The canonical media-heavy problem. Asked at Google L5+, Amazon L6+.
- Design Uber / ride-hailing. The canonical geospatial + matching problem. Asked at Meta, Google.
- Design Dropbox / file sync. The canonical sync + chunking problem. Asked at Google, Stripe.
- Design Google Docs / collaborative editing. The canonical CRDT / OT problem. Asked at Google L5+.
- Design TikTok feed / recommendation. The canonical ML-system-design problem. Asked at Meta, OpenAI L5+.
Each gets its own dedicated post in the company-specific guides. For L4-L5 prep, pick 4-5 from this list and walk them end-to-end with the RESHADED framework.
L3 vs L4 vs L5 vs L6 vs L7 leveling rubric
The same prompt ("design Twitter") gets evaluated differently by level. Here's what each level needs to demonstrate.
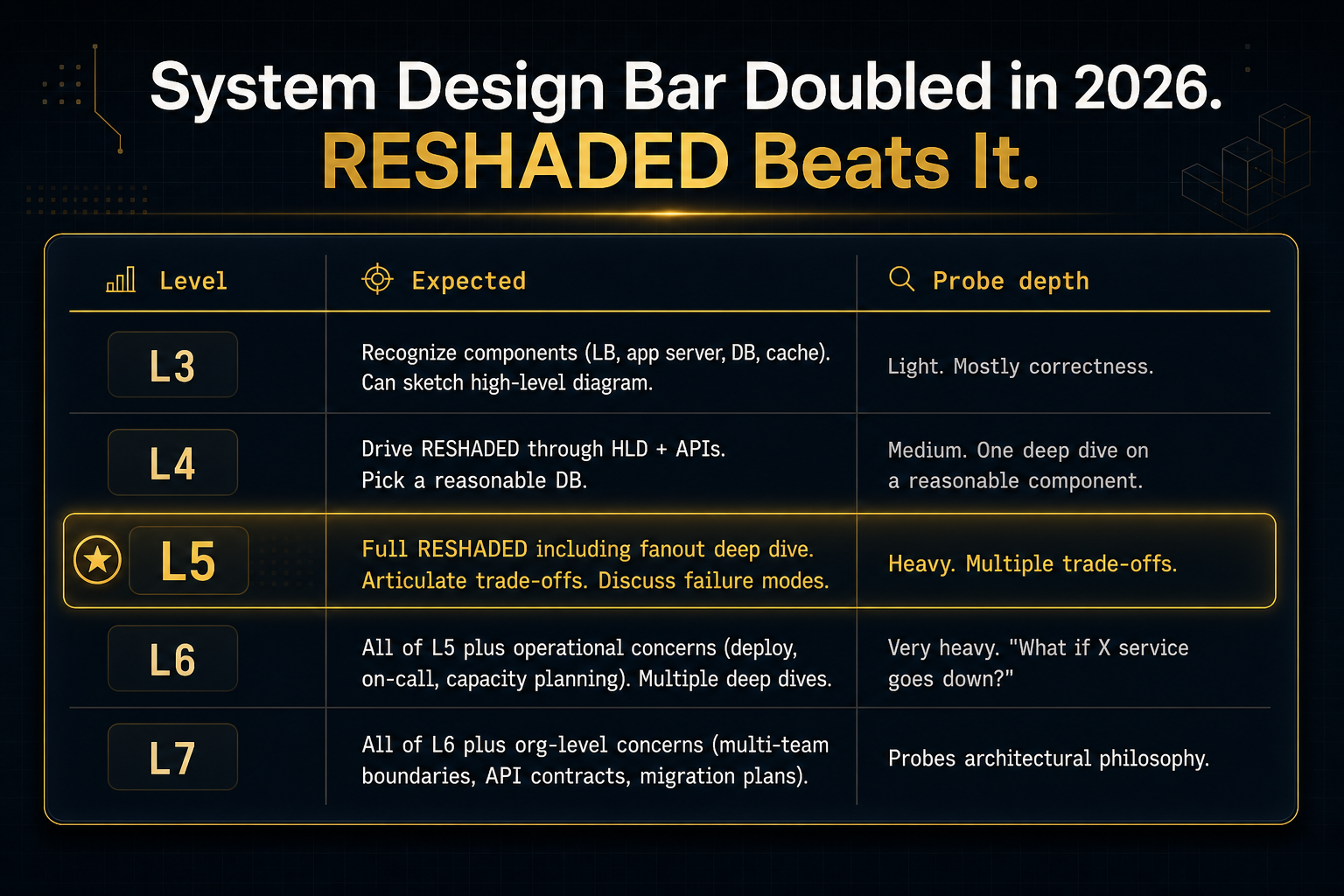
| Level | Expected | Probe depth |
|---|---|---|
| L3 | Recognize components (LB, app server, DB, cache). Can sketch high-level diagram. | Light. Mostly correctness. |
| L4 | Drive RESHADED through HLD + APIs. Pick a reasonable DB. | Medium. One deep dive on a reasonable component. |
| L5 | Full RESHADED including fanout deep dive. Articulate trade-offs. Discuss failure modes. | Heavy. Multiple trade-offs. |
| L6 | All of L5 plus operational concerns (deploy, on-call, capacity planning). Multiple deep dives. | Very heavy. "What if X service goes down?" |
| L7 | All of L6 plus org-level concerns (multi-team boundaries, API contracts, migration plans). | Probes architectural philosophy. |
Prepping for L4 and you walk an L5-quality deep dive? You've cleared the bar with room to spare. Prepping for L5 and you stop at HLD? You've underperformed.
What changed in 2026
Three updates to the standard pre-2024 SD curriculum:
- AI-augmented engineering boundaries. L5+ interviewers now probe "how does your team integrate AI tooling?" Be ready to discuss code-review AI, test generation AI, on-call AI assistants. (Not in any pre-2024 SD course.)
- Vector DBs and embedding services. L5+ interviews increasingly include "how would you add semantic search to this?" Be ready to discuss Pinecone, Weaviate, pgvector, embedding generation pipeline.
- LLM serving infrastructure. Specifically at OpenAI, Anthropic, and ML-team teams at Google/Meta. Be ready to discuss GPU scheduling, batch inference, KV cache.
For ML-system design specifically (recommendation systems, ranking systems), see the dedicated dive in our company-specific guides.
Recommended SD curriculum (8-12 weeks)
A focused 8-12 week SD curriculum:
- Weeks 1-2: RESHADED framework. Practice on URL Shortener and Pastebin.
- Weeks 3-4: Distributed systems primer. CAP, consistency models, replication, sharding. Read ByteByteGo Vol 1 chapters 1-4.
- Weeks 5-6: Walk Twitter and WhatsApp end-to-end. Watch Hello Interview videos for both.
- Weeks 7-8: Walk YouTube and Uber end-to-end.
- Weeks 9-10: ML-system design (recommendation, ranking, search). Read [the relevant Hello Interview content].
- Weeks 11-12: Mock interviews. interviewing.io paid mocks for SD calibration.
Resources
The 2026 SD resource stack:
- ByteByteGo Vol 1 + Vol 2. The curriculum. ~$25/mo subscription or buy the books.
- Hello Interview YouTube. Free walkthroughs of canonical designs.
- Designgurus Grokking System Design Interview. $79 lifetime, pattern-organized.
- System Design Primer (donnemartin/system-design-primer GitHub). Free reference.
- interviewing.io paid mocks. Calibration for the actual FAANG bar. $225 per 2-hr mock.
- FaangCoder for SD voice-mode. Paired SD walkthrough with Claude 4.7 (1M context). $399 lifetime. See the Solve demo.
2026 FAANG expectations
The 2026 interviewer expectation summary:
- L4: Walk through RESHADED in 35 minutes. Pick one deep dive. Articulate one trade-off.
- L5: Walk RESHADED in 40 minutes. Two deep dives. Three trade-offs. Failure mode discussion.
- L6+: All of L5 plus operational concerns. "What's your on-call playbook for this?" Multi-region considerations. Capacity planning math.
Common SD interview mistakes
After watching candidates fail SD interviews for the same reasons over and over:
Mistake 1: Skipping requirements. Jumping to design without 5 minutes of clarifying questions. Fix: force yourself to ask 4 questions before drawing anything.
Mistake 2: Over-precise estimation. Computing exact QPS to three significant figures. Fix: order-of-magnitude only. Round generously.
Mistake 3: Showing off database knowledge. Listing every NoSQL DB you've heard of. Fix: pick one with a reason. "Cassandra for tweets. Write throughput, sharding by user_id."
Mistake 4: No deep dive. Stopping after HLD. Fix: volunteer the deep dive. Pick the highest-leverage component.
Mistake 5: No failure modes. Designing only the happy path. Fix: explicitly discuss "what if Redis goes down?"
FAQ
Do I need to memorize a database trivia list? No. You need to know 4-5 databases well enough to pick one with reasoning. Cassandra/DynamoDB (wide column), Redis (cache), Postgres/MySQL (relational), Elasticsearch (search), S3 (object). That's the floor.
Should I draw on a whiteboard or in the shared editor? Shared editor for virtual interviews. Use Excalidraw or the platform's built-in. Practice with whichever your interview is on.
How long should I spend on each step? Total 35-40 minutes for L4, 45 minutes for L5. R: 5-7. E: 3-5. S: 5-7. H: 5-7. A: 3-5. D (deep dive): 10-15. E (edge cases): 3-5. D (done): 1-2.
Is system design harder than coding interviews? Different. SD has fewer right answers, more trade-offs. Easier in some ways (no off-by-one bugs). Harder in others (you have to articulate clearly under pressure).
What about ML system design? Increasingly common at L5+ specifically at Meta, Google, Anthropic, OpenAI. We have a dedicated guide coming.
The verdict
System design is the round that separates seniors from juniors and staff from seniors. The RESHADED framework + 4-5 worked designs + 8-12 weeks of focused practice + a few mock interviews puts you at L4 cleanly. Add operational depth and multiple deep dives for L5+. The 2026 bar is higher than 2022. Budget accordingly.
If you found this useful, FaangCoder helps candidates iterate to optimal solutions in real interviews. That includes paired system design walkthrough with Claude 4.7. $399 lifetime ($199/mo monthly option). See the Solve demo, or join the Discord to talk to other candidates working through SD prep.